T1
100%
用循环语句输入 A i A_i A i x x x A i = x A_i=x A i = x 1 1 1
注意数据范围,x x x A i A_i A i long long \text{long long} long long
时间复杂度 O ( n ) O(n) O ( n )
T2
100%
两重循环,外层循环枚举数组第 i i i A i A_i A i k k k
注意取模,计算其中一项 k k k int \text{int} int
时间复杂度 O ( n k ) O(nk) O ( nk )
T3
50%
记 V = min ( a , b ) V=\min(a,b) V = min ( a , b )
直接从 1 1 1 V V V x x x x x x a a a b b b x x x
时间复杂度 O ( V ) O(V) O ( V )
60%
对于测试点#6 ,因为 a = b a=b a = b a a a b b b a a a a a a
找 a a a x x x a \sqrt{a} a x x x a a a a x \frac{a}{x} x a a a a x = a x x=\frac{a}{x} x = x a
时间复杂度 O ( a ) O(\sqrt {a}) O ( a )
结合第一部分可以拿到 60 % 60\% 60%
100%
先求出 a a a b b b c = gcd ( a , b ) c=\gcd(a,b) c = g cd( a , b ) a a a b b b c c c c ≤ V c\leq V c ≤ V
找 c c c c \sqrt{c} c
时间复杂度 O ( V ) O(\sqrt {V}) O ( V )
T4
30%
假设 a , b , c a,b,c a , b , c l e n a ≤ l e n b ≤ l e n c len_a\leq len_b\leq len_c l e n a ≤ l e n b ≤ l e n c l e n a + l e n b > l e n c len_a+len_b>len_c l e n a + l e n b > l e n c 0 0 0
直接三重循环枚举三根木棍,用上述规则进行判断,符合则答案增加 1 1 1
注意三根木棍编号不能相同,还要避免重复枚举同一个方案。
时间复杂度 O ( n 3 ) O(n^3) O ( n 3 )
50%
将木棍按照长度从短到长排序。
先用两重循环枚举更短的两根木棍 a a a b b b a < b a<b a < b l e n c < l e n a + l e n b len_c<len_a+len_b l e n c < l e n a + l e n b a , b a,b a , b 0 0 0
要避免重复枚举同一方案,所以只有满足 c > b c>b c > b c c c
时间复杂度 O ( n 2 log ( n ) ) O(n^2\log(n)) O ( n 2 log ( n ))
70%
对于测试点#6~7 ,预处理长度不超过 x x x s u m [ x ] sum[x] s u m [ x ]
用两重循环枚举 a a a b b b c c c s u m [ l e n a + l e n b − 1 ] − b sum[len_a+len_b-1]-b s u m [ l e n a + l e n b − 1 ] − b
注意虽然 l e n len l e n 10 6 10^6 1 0 6 l e n a + l e n b len_a+len_b l e n a + l e n b 2 × 10 6 2\times 10^6 2 × 1 0 6 s u m sum s u m 2 × 10 6 2\times 10^6 2 × 1 0 6 l e n a + l e n b > 10 6 len_a+len_b>10^6 l e n a + l e n b > 1 0 6
记 l e n i len_i l e n i L = max { l e n i } L=\max\{len_i\} L = max { l e n i }
时间复杂度 O ( L + n 2 ) O(L+n^2) O ( L + n 2 )
结合第二部分可以拿到 70 % 70\% 70%
100%
当 a a a b b b l e n a + l e n b len_a+len_b l e n a + l e n b
所以在木棍按长度排序之后,我们可以把 b b b c c c b b b c c c c = n c=n c = n l e n a + l e n b ≤ l e n c + 1 len_a+len_b\leq len_{c+1} l e n a + l e n b ≤ l e n c + 1
相当于在第二部分的基础上,用双指针代替二分法,来求出有多少根木棍可以作为 c c c
时间复杂度 O ( n 2 ) O(n^2) O ( n 2 )
T5
20%
枚举每个知识点学与不学,那么共有 2 n 2^n 2 n O ( n ) O(n) O ( n )
时间复杂度 O ( 2 n n ) O(2^nn) O ( 2 n n )
60%
因为每个知识点最多只会有一个前置知识点,可以把这类前置关系看成树的结构,p i p_i p i i i i
用 d p [ i ] [ j ] dp[i][j] d p [ i ] [ j ] i i i j j j x x x y y y t m p [ x ] [ i ] tmp[x][i] t m p [ x ] [ i ] x x x 已经处理过的部分 (即不包括 y y y i i i t m p [ x ] [ a + b ] = max { t m p [ x ] [ a ] + d p [ y ] [ b ] } tmp[x][a+b]=\max\{tmp[x][a]+dp[y][b]\} t m p [ x ] [ a + b ] = max { t m p [ x ] [ a ] + d p [ y ] [ b ]} a a a 1 1 1 x x x
由于可能存在多个 p i = 0 p_i=0 p i = 0 0 0 0 d p [ 0 ] [ m + 1 ] dp[0][m+1] d p [ 0 ] [ m + 1 ]
实际实现中,t m p tmp t m p d p dp d p a + b a+b a + b s = a + b s=a+b s = a + b
for (int s = m + 1; s >= 1; s--)
for (int b = 1; b < s; b++) {
int a = s - b;
dp[x][s] = max(dp[x][s], dp[x][a] + dp[y][b]);
}
时间复杂度 O ( n 3 ) O(n^3) O ( n 3 )
100%
用 s i z [ i ] siz[i] s i z [ i ] i i i t m p s i z [ i ] tmpsiz[i] t m p s i z [ i ] i i i 已经处理过的部分 中知识点的数量。
如果限制 a ≤ t m p s i z [ x ] a\leq tmpsiz[x] a ≤ t m p s i z [ x ] b ≤ s i z [ y ] b\leq siz[y] b ≤ s i z [ y ] O ( n 2 ) O(n^2) O ( n 2 )
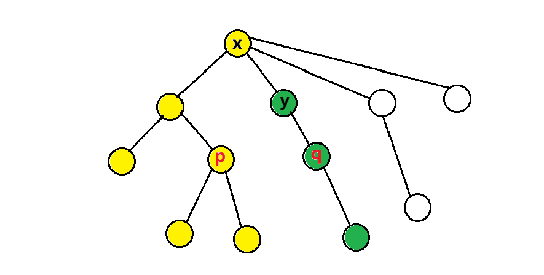
这一过程的复杂度等价于在两个部分各选一个点的方案数,不难发现任意一对点在这个过程中只会在LCA(最近公共祖先)处被考虑一次,所以总复杂度是 O ( n 2 ) O(n^2) O ( n 2 )
如下图,点对 ( p , q ) (p,q) ( p , q ) L C A ( p , q ) = x LCA(p,q)=x L C A ( p , q ) = x x x x 已经处理过的部分 ,绿色点是以 y y y
参考代码如下:
for (int s = siz[x] + siz[y]; s >= 1; s--) {
for (int b = max(s - siz[x], 0); b <= siz[y] && b < s; b++) {
int a = s - b;
dp[x][s] = max(dp[x][s], dp[x][a] + dp[y][b]);
}
时间复杂度 O ( n 2 ) O(n^2) O ( n 2 )
T6
10%
三重循环,外层两重循环枚举子区间 [ l , r ] [l,r] [ l , r ] s u m A ( l , r ) = ∑ i = l r A i sumA(l,r)=\sum_{i=l}^{r} A_i s u m A ( l , r ) = ∑ i = l r A i a v g ( l , r ) ≥ x avg(l,r)\geq x a vg ( l , r ) ≥ x
注意取模。
可以不计算平均值,用区间和直接与 x × ( r − l + 1 ) x\times (r-l+1) x × ( r − l + 1 )
时间复杂度 O ( n 3 ) O(n^3) O ( n 3 )
30%
预处理前缀和,就可以 O ( 1 ) O(1) O ( 1 )
时间复杂度 O ( n 2 ) O(n^2) O ( n 2 )
50%
处理出数组 B i = A i − x B_i=A_i-x B i = A i − x B i B_i B i s u m B ( l , r ) = ∑ i = l r B i sumB(l,r)=\sum_{i=l}^{r} B_i s u m B ( l , r ) = ∑ i = l r B i [ l , r ] [l,r] [ l , r ] s u m B ( l , r ) ≥ 0 sumB(l,r)\geq 0 s u m B ( l , r ) ≥ 0
枚举子区间右端点 r r r s u m B ( l , r ) ≥ 0 sumB(l,r)\geq 0 s u m B ( l , r ) ≥ 0 l l l s u m A ( l , r ) sumA(l,r) s u m A ( l , r )
在这个基础上,把 s u m A ( l , r ) sumA(l,r) s u m A ( l , r ) s u m A ( 1 , r ) sumA(1,r) s u m A ( 1 , r ) − s u m A ( 1 , l − 1 ) -sumA(1,l-1) − s u m A ( 1 , l − 1 )
s u m B ( l , r ) ≥ 0 sumB(l,r)\geq 0 s u m B ( l , r ) ≥ 0 s u m B ( 1 , r ) ≥ s u m B ( 1 , l − 1 ) sumB(1,r)\geq sumB(1,l-1) s u m B ( 1 , r ) ≥ s u m B ( 1 , l − 1 ) r r r l l l
那么第一部分对答案贡献的次数为对于 r r r l l l
第二部分对答案的总贡献为每个对于 r r r l l l − s u m A ( 1 , l − 1 ) -sumA(1,l-1) − s u m A ( 1 , l − 1 )
将 B i B_i B i s u m B ( 1 , i ) = j sumB(1,i)=j s u m B ( 1 , i ) = j i i i ∑ s u m A ( 1 , i − 1 ) \sum sumA(1,i-1) ∑ s u m A ( 1 , i − 1 ) r r r
记 B i B_i B i V = max { s u m B ( 1 , i ) } − min { s u m B ( 1 , i ) } V=\max\{sumB(1,i)\}-\min\{sumB(1,i)\} V = max { s u m B ( 1 , i )} − min { s u m B ( 1 , i )}
时间复杂度 O ( n log ( V ) ) O(n\log(V)) O ( n log ( V ))
结合第二部分可以拿到 50 % 50\% 50%
60%
对于测试点#6 ,因为 x ≤ min { A i } x\leq \min\{A_i\} x ≤ min { A i }
答案就等于所有子区间的区间和之和。
时间复杂度 O ( n ) O(n) O ( n )
结合第二、第三部分可以拿到 60 % 60\% 60%
100%
在第三部分的基础上,将下标域扩展到 [ − 10 12 , 10 12 ] [-10^{12},10^{12}] [ − 1 0 12 , 1 0 12 ]
使用动态开点的权值线段树。
时间复杂度 O ( n log ( V ) ) O(n\log(V)) O ( n log ( V ))
计算出 B i B_i B i
时间复杂度 O ( n log ( n ) ) O(n\log(n)) O ( n log ( n ))